



I. Introduction▲
Il existe deux types d'applications pour Android. Le premier type correspond à l'application Dalvik qui est basée sur Java et qui peut tourner correctement sur n'importe quelle architecture sans aucune modification. Le second type concerne les applications NDK dont une partie du code est écrite en C/C++ ou ASM et qui doivent être compilées pour un processeur spécifique.
Cette discussion sera axée sur les applications NDK. On a généralement juste besoin de modifier le paramètre APPABI, dans le fichier application.mk et de compiler la partie NDK, ce qui lui permettra, par la suite, d'être exécuté sur le périphérique correspondant. Cependant, certaines parties des applications NDK ne peuvent pas être simplement compilées à nouveau si elles contiennent certains types de codes, comme un code en langage assembleur ou un code à instruction unique et données multiples (SIMD : Single Instruction Multiple Data).
Cet article explique comment traiter ces problèmes et présente les majeures considérations que les développeurs doivent connaitre sur le fait de porter une application de plate-forme d'architecture non Intel (x86) sur une plate-forme d'architecture Intel. On traitera également la conversion de boutisme du x86 vers les plates-formes non x86.
II. Instruction unique et données multiples (SIMD)▲
SIMD (Single Instruction Multiple Data) est une classe d'ordinateurs parallèles, comme décrit par la taxonomie de Flynn, avec de multiples éléments de traitement qui effectuent la même opération sur plusieurs points de données simultanément. Ces machines exploitent le parallélisme des données, car il y a simultanément des calculs. SIMD est particulièrement adéquat sur des tâches courantes telles que le réglage du contraste dans une image numérique, ou le réglage du volume du son numérique.
La plupart des modèles de processeurs incluent les instructions SIMD afin d'améliorer les performances pour une utilisation multimédia. Pour la plate-forme x86 mobile, SIMD est appelé « Intel Streaming SIMD Extensions » (Intel® SSE, SSE2, SSE3, etc.). Pour la plate-forme ARM*, SIMD est appelé « NEON technology ». Si vous avez besoin d'informations sur NEON, référez-vous à la documentation du constructeur.
II-A. Intel® Streaming SIMD Extensions (Intel® SSE)▲
D'abord, qu'est-ce que Intel SSE ? C'est essentiellement une collection de registres de processeur 128 bits. Ces registres peuvent être représentés en quatre scalaires de 32 bits qui permettent à une opération d'être effectuée sur chacun des quatre éléments simultanément.
En revanche, ça peut prendre quatre opérations ou plus en assembleur régulier pour faire la même chose. Dans le diagramme ci-dessous, vous pouvez voir deux vecteurs (registres Intel SSE) représentés avec des scalaires. Les registres sont multipliés avec MULPS qui stocke le résultat. Voilà quatre multiplications réduites en une seule opération. L'intérêt d'utiliser Intel SSE est suffisamment important pour ne pas être ignoré.
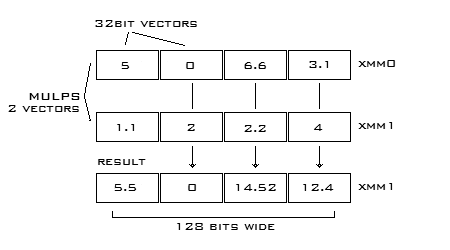
Maintenant, avec l'idée de base d'Intel SSE en tête, nous allons jeter un coup d'œil à quelques-unes des instructions les plus courantes.
|
Les instructions de mouvement de données |
|
|
MOVUPS |
Déplacer 128 bits de données vers un registre SIMD de la mémoire ou registre SIMD. Non-aligné. |
|
MOVAPS |
Déplacer 128 bits de données vers un registre SIMD de la mémoire ou registre SIMD. Aligné. |
|
MOVHPS |
Déplacer 64 bits à des bits supérieurs d'un registre SIMD (élevé). |
|
MOVLPS |
Déplacer 64 bits à bits de poids faible d'un registre SIMD (bas). |
|
MOVHLPS |
Déplacer les 64 bits supérieurs du registre source vers 64 bits inférieurs du registre de destination. |
|
MOVLHPS |
Déplacer les 64 bits inférieurs du registre source vers 64 bits supérieurs du registre de destination. |
|
MOVMSKPS |
Déplacer les bits de signe de chacun des quatre scalaires emballés vers un registre x86 d'entiers. |
|
MOVSS |
Déplacer 32 bits à un registre SIMD de la mémoire ou du registre SIMD. |
|
Instructions arithmétiques |
||
|
NOTE : un scalaire va effectuer l'opération uniquement sur les premiers éléments. La version parallèle va effectuer l'opération sur tous les éléments dans le registre. |
||
|
Parallèle |
Scalaire |
Description |
|
ADDPS |
ADDSS |
additionne les opérandes. |
|
SUBPS |
SUBSS |
soustrait les opérandes. |
|
MULPS |
MULSS |
multiplie les opérandes. |
|
DIVPS |
DIVSS |
divise les opérandes. |
|
SQRTPS |
SQRTSS |
racine carrée de l'opérande. |
|
MAXPS |
MAXSS |
Maximum des opérandes. |
|
MINPS |
MINSS |
Minimum des opérandes. |
|
RCPPS |
RCPSS |
inverse de l'opérande. |
|
RSQRTPS |
RSQRTSS |
inverse de la racine carrée de l'opérande. |
|
Instructions de comparaison |
|
|
Parallèle |
Scalaire |
|
CMPPS, CMPSS |
Compare les opérateurs et retourne tout à 1 ou tout à 0. |
|
Instructions logiques |
|
|
ANDPS |
ET bit à bit des opérandes. |
|
ANDNPS |
NON-ET bit à bit des opérandes. |
|
ORPS |
OU bit à bit des opérandes. |
|
XORPS |
OU exclusive des opérandes. |
|
Instructions aléatoires |
|
|
SHUFPS |
Mélanger les nombres d'un opérande à un autre ou lui-même. |
|
UNPCKHPS |
Déballer les nombres d'ordre élevé pour un registre SIMD. |
|
UNPCKLPS |
Déballer les nombres d'ordre bas pour un registre SIMD. |
D'autres instructions non traitées ici incluent la conversion des données entre le x86 et les registres MMX, les instructions de contrôle de la cache et les instructions de la gestion du statut.
III. Comment convertir NEON en Intel SSE ?▲
Les instructions Intel SSE et NEON ne sont pas parfaitement équivalentes. Bien que basée sur le même principe de conception, la méthode d'implémentation est différente. Vous devez traduire chaque instruction une par une.
Le code suivant utilise les instructions NEON :
int16x8_t q0 = vdupq_n_s16(-1000), q1 = vdupq_n_s16(1000);
int16x8_t zero = vdupq_n_s16(0);
for( k = 0; k < 16; k += 8 )
{
int16x8_t v0 = vld1q_s16((const int16_t*)(d+k+1));
int16x8_t v1 = vld1q_s16((const int16_t*)(d+k+2));
int16x8_t a = vminq_s16(v0, v1);
int16x8_t b = vmaxq_s16(v0, v1);
v0 = vld1q_s16((const int16_t*)(d+k+3));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k+4));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k+5));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k+6));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k+7));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k+8));
a = vminq_s16(a, v0);
b = vmaxq_s16(b, v0);
v0 = vld1q_s16((const int16_t*)(d+k));
q0 = vmaxq_s16(q0, vminq_s16(a, v0));
q1 = vminq_s16(q1, vmaxq_s16(b, v0));
v0 = vld1q_s16((const int16_t*)(d+k+9));
q0 = vmaxq_s16(q0, vminq_s16(a, v0));
q1 = vminq_s16(q1, vmaxq_s16(b, v0));
}
q0 = vmaxq_s16(q0, vsubq_s16(zero, q1));
// première erreur, ça produit un mauvais résultat
//q0 = vmaxq_s16(q0, vzipq_s16(q0, q0).val[1]);
// peut être que quelqu'un connait une meilleure méthode?
int16x4_t a_hi = vget_high_s16(q0);
q1 = vcombine_s16(a_hi, a_hi);
q0 = vmaxq_s16(q0, q1);
// Ceci est _mm_srli_si128(q0, 4)
q1 = vextq_s16(q0, zero, 2);
q0 = vmaxq_s16(q0, q1);
// Ceci est _mm_srli_si128(q0, 2)
q1 = vextq_s16(q0, zero, 1);
q0 = vmaxq_s16(q0, q1);
// lire le résultat
int16_t __attribute__ ((aligned (16))) x[8];
vst1q_s16(x, q0);
threshold = x[0] - 1;Le code suivant utilise Intel SSE :
__m128i q0 = _mm_set1_epi16(-1000), q1 = _mm_set1_epi16(1000);
for( k = 0; k < 16; k += 8 )
{
__m128i v0 = _mm_loadu_si128((__m128i*)(d+k+1));
__m128i v1 = _mm_loadu_si128((__m128i*)(d+k+2));
__m128i a = _mm_min_epi16(v0, v1);
__m128i b = _mm_max_epi16(v0, v1);
v0 = _mm_loadu_si128((__m128i*)(d+k+3));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k+4));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k+5));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k+6));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k+7));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k+8));
a = _mm_min_epi16(a, v0);
b = _mm_max_epi16(b, v0);
v0 = _mm_loadu_si128((__m128i*)(d+k));
q0 = _mm_max_epi16(q0, _mm_min_epi16(a, v0));
q1 = _mm_min_epi16(q1, _mm_max_epi16(b, v0));
v0 = _mm_loadu_si128((__m128i*)(d+k+9));
q0 = _mm_max_epi16(q0, _mm_min_epi16(a, v0));
q1 = _mm_min_epi16(q1, _mm_max_epi16(b, v0));
}
q0 = _mm_max_epi16(q0, _mm_sub_epi16(_mm_setzero_si128(), q1));
q0 = _mm_max_epi16(q0, _mm_unpackhi_epi64(q0, q0));
q0 = _mm_max_epi16(q0, _mm_srli_si128(q0, 4));
q0 = _mm_max_epi16(q0, _mm_srli_si128(q0, 2));
threshold = (short)_mm_cvtsi128_si32(q0) - 1;Pour plus d'informations à propos de la conversion NEON en Intel SSE, référez-vous au blog cité dans la section références [1]. Il fournit un fichier d'en-tête qui peut être utilisé pour créer automatiquement une carte des instructions NEON et Intel SSE.
IV. Activer le langage Assembleur▲
Les microprocesseurs à jeu d'instruction étendu (Complex Instruction Set Computer : CISC), comme ceux d'Intel, ont un ensemble d'instructions riches et capables d'effectuer des actions complexes avec une instruction unique (contrairement à l'architecture RISC qui vise des instructions plus généralistes ainsi que l'efficacité). Les instructions CISC ont un nombre relativement important de registres à usage généraliste, et d'instructions de données qui utilisent généralement trois registres : une destination et deux opérandes. Si vous avez besoin d'informations sur les instructions/l'architecture ARM, référez-vous à la documentation du constructeur.
Les processeurs Intel (cf. 386 et plus) ont huit registres 32 bits à usage général comme montré dans le diagramme suivant. Les noms d'un registre sont pour la plupart historiques. Par exemple, EAX était appelé « l'accumulateur » puisqu'il était utilisé par un certain nombre d'opérations arithmétiques ; ECX était connu sous le nom de « calculateur » puisqu'il était utilisé pour maintenir un indice de boucle. Alors que la plupart des registres ont perdu leurs fins spéciales dans le jeu d'instructions modernes ; par convention, deux sont réservés à des fins particulières : le pointeur de pile (ESP) et le pointeur de base (EBP).
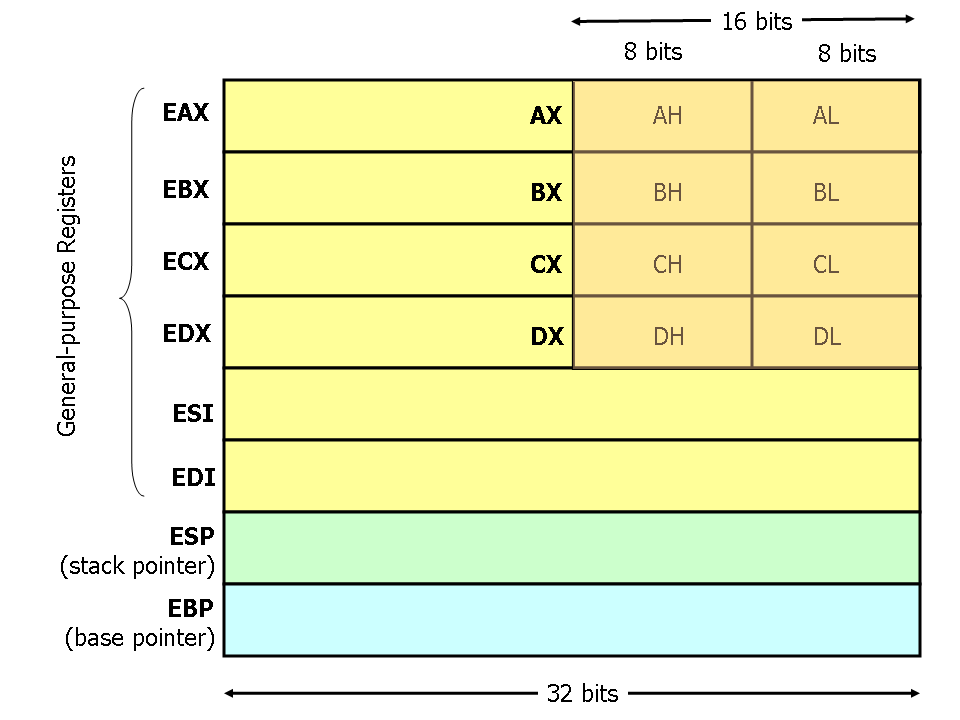
Pour les registres EAX, EBX, ECX et EDX, des sous-ensembles peuvent être utilisés. Par exemple, les deux octets les moins significatifs de EAX peuvent être traités comme un registre de 16 bits appelé AX. L'octet le moins significatif de AX peut être utilisé comme un simple registre de 8 bits appelé AL, tandis que l'octet le plus significatif de AX peut être utilisé comme un simple registre de 8 bits appelé AH. Ces noms font référence au même registre physique. Quand une quantité de deux octets est placée dans DX, la mise à jour affecte la valeur de DH, DL et EDX. Ces sous-registres sont principalement les restants des anciennes versions 16 bits du jeu d'instructions. Cependant, ils sont parfois appropriés lorsqu'il s'agit de données qui sont plus petites que 32 bits (par exemple, les caractères ASCII sur un octet).
Puisqu'il y a des différences entre ARM et le langage assembleur x86, le code assembleur ARM ne peut pas être utilisé directement sur les plates-formes x86 :
- Implémenter la même fonction avec le langage assembleur x86 ;
- Remplacer le code ARM avec le code C.
Dans de nombreux programmes Open Source, le code ASM a été remplacé pour améliorer les performances, mais la performance n'est pas un problème dans ce cas, car les processeurs sont plus robustes que jamais. Cependant, contrairement au code ASM écrasé, le code C qui a implémenté la même fonction a été retenu dans le code source, cela nous permet de compiler du code C pour une plate-forme x86.
Par exemple, un éditeur de logiciels a développé un jeu qui utilise le format de compression audio Vorbis, un programme open source qui contient du code segmenté assembleur ARM. Donc, l'éditeur de logiciels n'a pas pu le convertir en x86 NDK. Au lieu d'avoir à réécrire cette section de code x86 ASM, le développeur la recompile en C de sorte qu'il s'exécute correctement sur x86. Le problème a été résolu en désactivant la macro_ARM_ASSEM_ et en activant la macro _LOW_ACCURACY_.
IV-A. La conversion du boutisme en ARM et x86▲
Dans les projets multiplateformes, nous sommes souvent confrontés à un vieux problème de conversion de boutisme. Si le fichier est généré sur une machine petit boutiste, un entier 255 peut être stocké comme suit :
ff 00 00 00Mais quand la valeur est lue dans la mémoire, elle sera différente pour diverses plates-formes, ce qui provoquera un problème de portage.
int a;
fread(&a, sizeof(int), 1, file);
// sur une machine petit boutiste, a = 0xff;
// mais sur une machine grand boutiste, a = 0xff000000;Une manière très simple et efficace de résoudre ce problème est d'écrire une fonction appelée readInt() :
void readInt(void* p, file)
{
char buf[4];
fread(buf, 4, 1, file);
*((uint32*)p) = buf[0] << 24 | buf[1] << 16
| buf[2] << 8 | buf[3];}La fonction a l'avantage de marcher sur les plates-formes grand boutiste et petit boutiste, mais elle est incompatible avec la méthode habituelle pour lire une structure.
fread(&header, sizeof(struct MyFileHeader), 1, file);Si MyFileHeader contient beaucoup d'entiers, ça va résulter en plusieurs read(). Ce n'est pas seulement lourd à coder, mais en plus c'est lent en raison de l'exploitation accrue des opérations d'entrée-sortie. Je propose donc une autre méthode : laissons le code inchangé et utilisons plusieurs macros pour traiter les données plus tard.
fread(&header, sizeof(struct MyFileHeader), 1, file);
CQ_NTOHL(header.version);
CQ_NTOHL_ARRAY(&header.box, 4); // box est une structure RECTSi le boutisme de l'ordinateur ne correspond pas à celle du fichier de données, ces macros seront soient définies pour exécuter certaines fonctions, soient définies vides :
#if defined(ENDIAN_CONVERSION)
# define CQ_NTOHL(a) {a = ((a) >> 24) | (((a) & 0xff0000) >> 8) | (((a) & 0xff00) << 8) | ((a) << 24); }
# define CQ_NTOHL_ARRAY(arr, num) {uint32 i;
for(i = 0; i < num; i++) {CQ_NTOHL(arr[i]); }}
#else
# define CQ_NTOHL(a)
# define CQ_NTOHL_ARRAY(arr, num)
#endifCette approche a l'avantage de ne pas perdre des cycles du processeur si ENDIAN_CONVERSION n'est pas défini, et le code peut être conservé dans sa forme naturelle de sorte à lire toute une structure à la fois.
IV-B. Conclusion▲
ARM et x86 possèdent une architecture et des ensembles d'instructions différentes, il y a donc des divergences dans les fonctionnalités de bas niveau. J'espère que les informations contenues dans cet article vont vous aider à surpasser ces différences lors du développement d'applications Android NDK pour plusieurs plates-formes.
Vous trouverez également d'autres outils pour optimiser les performances de vos applications sur l'Intel Developer Zone Android.
IV-C. À propos de l'auteur▲
Peng Tao (tao.peng@intel.com) est un ingénieur d'applications logicielles dans le groupe Intel Software and Services. Il se concentre actuellement sur les jeux et l'activation du multimédia sur les applications et l'optimisation des performances, en particulier sur les plates-formes mobiles Android.