


I. Partie 2. Amélioration du PIC (Position independent code) en mode 32 bits▲
Le PIC en mode 32 bits est utilisé pour développer des applications Android, des bibliothèques Linux et de nombreux autres produits. Dans cette perspective, les performances GCC sont ainsi très importantes.
GCC 5.0 pourrait apporter un gain significatif en termes de performances (jusqu'à 30 %) pour les applications comportant de gourmandes boucles itératives, telles que la cryptographie, la protection de données, la compression de données, les fonctions de hachage…là où la vectorisation n'est pas utilisable.
Dans GCC 4.9, le registre EBX est réservé pour l'adresse de la GOT (global offset table) et n'est donc pas disponible pour être alloué. De ce fait, le PIC en mode 32 bits n'a que six registres disponibles (contrairement aux sept registres habituels) : EAX, ECX, EDX, ESI, EDI et EBP. Cela entraîne des chutes de performances lorsqu'il n'y a pas assez de registres pour une allocation. Et ce d'autant plus qu'il arrive que EBP soit aussi réservé, entraînant une plus forte chute des performances.
Dans GCC 5.0, le registre EBX est redevenu allouable, rendant ainsi disponibles sept registres. Cela permet de booster les applications contenant des boucles itératives souffrant des restrictions de registre. Ci-dessous sont reportés les résultats d'un stress test souffrant d'un manque de registres disponibles dans une boucle itérative.
Code source de test :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
int i, j, k;
uint32 *in = a, *out = b;
for (i = 0; i < 1024; i++)
{
for (k = 0; k < ST; k++)
{
uint32 s = 0;
for (j = 0; j < LD; j++)
s += (in[j] * c[j][k] + 1) >> j + 1;
out[k] = s;
}
in += LD;
out += ST;
}
Où
- “c” est une matrice constante :
2.
3.
4.
5.
6.
7.
8.
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1,
1, 1, -1, -1, 1, 1, -1, -1,
1, 1, 1, 1, -1, -1, -1, -1,
-1, 1, -1, 1, -1, 1, -1, 1,
-1, -1, 1, 1, -1, -1, 1, 1,
-1, -1, -1, -1, 1, 1, 1, 1,
-1, -1, -1, 1, 1, 1, -1, 1,
1, -1, 1, 1, 1, -1, -1, -1};
- Les pointeurs “in“ et “out” renvoient vers les tableaux entiers "a[1024 * LD]" et "b[1024 * ST]".
- uint32 est un entier non signé.
- LD et ST : macros définissant le nombre de charges et de stockages dans la boucle externe.
Les options de compilation sont "-Ofast -funroll-loops -fno-tree-vectorize --param max-completely-peeled-insns=200" et "-march=slm" pour Silvermont, "-march=core-avx2" pour Haswell, "-fPIC" pour le mode PIC et "-DST=7 -DLD={4, 5, 6, 7, 8}".
"-fno-tree-vectorize" est utilisé pour éviter la vectorisation et donc l'utilisation des registres xmm.
"--param max-completely-peeled-insns=200" est utilisé pour rendre similaires les comportements de 5.0 et 4.9, 4.9 ayant ce paramètre réglé à 100.
Regardons tout d'abord à quel point GCC 5.0 est plus rapide que GCC 4.9 dans ce test (sachant que plus la valeur est élevée, mieux cela est).
L'axe horizontal indique le nombre de charges de la boucle : LD. Les valeurs de "LD" plus élevées mènent à une plus haute pression sur le registre.
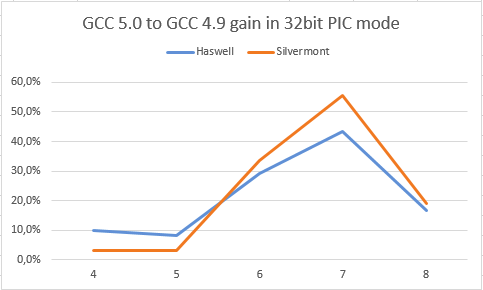
Nous pouvons ici observer que Silvermont et Haswell obtiennent tous deux un gain non négligeable sur la boucle. Pour être sûr que ce gain est causé par un retour du registre EBX vers l'allocation, observons les deux graphiques ci-dessous.
Le graphique ci-dessous nous montre un ralentissement (ou gain) en activant le mode PIC sur Haswell et Silvermont pour GCC 5.0 et GCC 4.9 (plus la valeur est élevée, mieux c'est).
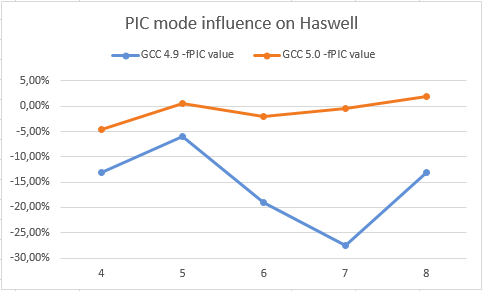
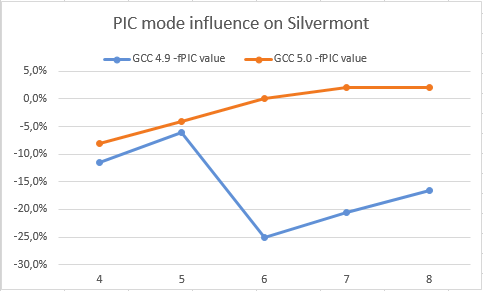
Ici, nous pouvons voir que GCC 5.0 ne perd pas beaucoup avec le mode PIC, mais GCC 4.9 perd autant sur Haswell que sur Silvermont. Cela signifie que GCC 5.0 devrait améliorer les performances de certaines boucles itératives. De plus, les développeurs d'aujourd'hui peuvent essayer des optimisations plus agressives (en termes de pression sur les registres) telles que le déroulage, l'alignement, une configuration agressive sur les invariants de boucles, la propagation de copie...
Vous pouvez trouver les compilateurs utilisés pour ces mesures sur :
Sources du test : Matrice à télécharger.
Pour toute question ou support additionnel, n'hésitez pas à la poser en commentaire ou sur le forum Intel Android.
Découvrez aussi l'ensemble des outils de développements Android, ainsi que de nombreux supports sur Intel Developer Zone Android.