


I. Partie 1 : Vectorisation des sections de load/store▲
GCC 5.0 améliore beaucoup la qualité du code des vecteurs pour les sections de load/store. Lorsque l'on parle de section de load/store, on entend par là une séquence consécutive de load/store. Par exemple :
x = a[i], y = a[i + 1], z = a[i + 2] itéré à l'aide de “i” est une section de load/store de taille 3.
La taille du groupe est la différence entre la plus petite et la plus grande adresse chargée/sauvegardée. Dans l'exemple (i + 2) - (i) + 1 = 3.
Le nombre de load/store dans un groupe est inférieur ou égal à la taille du groupe. Par exemple :
x = a[i], z = a[i + 2] itéré à l'aide de i est toujours une section de chargement de taille 3, mais n'a que deux loads.
GCC 4.9 vectorise les sections de toute taille ayant une puissance de 2 (2, 4, 8 …).
GCC 5.0 vectorise les sections de taille 3 et de toute taille ayant une puissance de 2 (2, 4, 8 …). Les autres tailles (5, 6, 7, 9…) sont rarement utilisées.
Le cas le plus fréquent d'utilisation de sections de load/store est un assortiment de structures.
-
Conversion d'image (d'une structure RGB à une autre)
(testez-la ici)
-
Coordonnées N-dimensionnelles (normaliser un ensemble de points XYZ)
(testez-le ici)
- Multiplication de vecteurs par une matrice constante :
- a[i][0] = 7 * b[i][0] - 3 * b[i][1] ;
- a[i][1] = 2 * b[i][0] + b[i][1].
Dans l'ensemble, GCC 5.0 :
- Intègre la vectorisation de sections de load/store de taille 3.
- Améliore la vectorisation des sections de chargement pour toutes les tailles prises en charge.
- Maximise la performance des sections de load/store en générant du code qui est optimisé pour les CPU x86.
Vous trouverez ci-dessous le tableau qui tente d'estimer l'impact des performances sur la structure d'octets (nombre maximum d'éléments dans un vecteur), comparant les performances de GCC 4.9 et GCC 5.0 sur la boucle suivante :
int i, j, k;
byte *in = a, *out = b;
for (i = 0; i < 1024; i++)
{
for (k = 0; k < STGSIZE; k++)
{
byte s = 0;
for (j = 0; j < LDGSIZE; j++)
s += in[j] * c[j][k];
out[k] = s;
}
in += LDGSIZE;
out += STGSIZE;
}Où
- c est la matrice constante :
2.
3.
4.
5.
6.
7.
8.
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1,
1, 1, -1, -1, 1, 1, -1, -1,
1, 1, 1, 1, -1, -1, -1, -1,
-1, 1, -1, 1, -1, 1, -1, 1,
-1, -1, 1, 1, -1, -1, 1, 1,
-1, -1, -1, -1, 1, 1, 1, 1,
-1, -1, -1, 1, 1, 1, -1, 1,
1, -1, 1, 1, 1, -1, -1, -1};
Utilisée pour simplifier les calculs dans la boucle pour seulement add et sub, ce qui est souvent très rapide.
- in et out pour les pointeurs pour les tableaux globaux a[1024 * LDGSIZE] et b[1024 * STGSIZE] ;
- byte est un unsigned char ;
- LDGSIZE et STGSIZE - macros définissant la taille des groupes de charges et données.
Les options de compilation sont -Ofast et -march=slm pour Silvermont, -march=core-avx2 pour Haswell et toutes les combinaisons de -DLDGSIZE={1,2,3,4,8} -DSTGSIZE={1,2,3,4,8}
GCC 5.0 à 4.9 (en coefficient multiplicateur, plus le nombre est élevé meilleur est le gain) :
Silvermont : Intel(R) Atom(TM) CPU C2750 @ 2.41GHz
Le gain de temps atteint un coefficient de 6.5 !
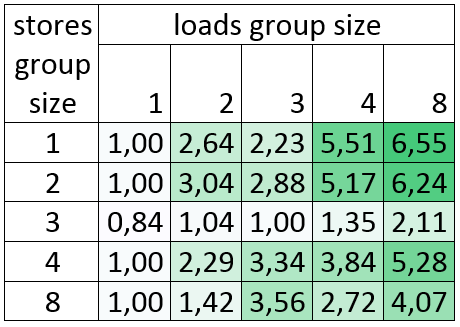
Comme on peut le voir, les résultats pour les sections de store de taille 3 ne sont pas aussi satisfaisants. C'est parce que la vectorisation des sections de store de taille 3 nécessite huit instructions pshufb qui prennent cinq cycles sur Silvermont. Cependant, la boucle est vectorisée, et s'il y avait des calculs plus complexes dans la boucle, la vectorisation aurait un gain plus important (on peut le voir pour les groupes de tailles 2, 3, 4 et 8).
Haswell: Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz
Le gain peut aller jusqu'à un coefficient de 3 !

Comme les instructions pshufb ne prennent qu'un cycle sur Haswell, les résultats sont bien meilleurs pour des sections de sauvegarde de taille 3. C'est la plus grande amélioration que nous puissions voir pour les nouvelles sections de load/store de taille 3.
Vous pouvez trouver les compilateurs utilisés pour les mesures sur :
Sources du test : Matrice à télécharger.
Pour toute question ou tout support additionnel, n'hésitez pas à la poser en commentaire ou sur le forum Intel Android.
Découvrez aussi l'ensemble des outils de développements Android, ainsi que de nombreux supports sur Intel Developer Zone Android.