



I. Introduction▲
Dans cet article, nous allons utiliser un exemple que vous pouvez télécharger ici : exemple à télécharger.
Cet exemple présente l'utilisation de l'extension GL_INTEL_fragment_shader_ordering, reposant sur le profil core OpenGL 4.4 et des spécifications OpenGL ES 3.1. La version minimale requise est OpenGL 4.2 ou toute implémentation supportant l'extension ARB_shader_image_load_storebeginFragmentShaderOrderingINTEL(). L'extension introduit une nouvelle fonction GLSL, beginFragmentShaderOrderingINTEL(), laquelle bloque l'invocation du fragment shader jusqu'à ce que les invocations des primitives précédentes aux mêmes coordonnées de fenêtre soient complétées. L'exemple fait usage de ce comportement pour fournir une solution temps réel de transparence indépendante de l'ordre de rendu (Order-Independant Transparency) dans une scène 3D.
II. Transparence indépendante de l'ordre de rendu▲
La transparence est une problématique difficulté dans un rendu temps réel, en raison de la difficulté à composer un nombre arbitraire de couches de transparence dans le bon ordre. Cet exemple s'appuie sur le travail présenté dans les articles transparence adaptative et le mélange alpha sur plusieurs couches de Marko Salvi, Jefferson Montgomery, Karthik Vaidyanathan, et Aaron Lefohn. Ces articles montrent comment la transparence peut se rapprocher de la réalité obtenue depuis un A-Buffer, mais en étant entre 5 à 40 fois plus rapide en utilisant plusieurs techniques de compression sans perte sur les données de transparence. L'exemple présente un algorithme basé sur ces techniques de compression, transformé pour être inclus dans une application temps réel telle qu'un jeu.
III. Le défi de la transparence▲
Le rendu de la scène utilisant une transparence normale est montré dans la figure 1 :
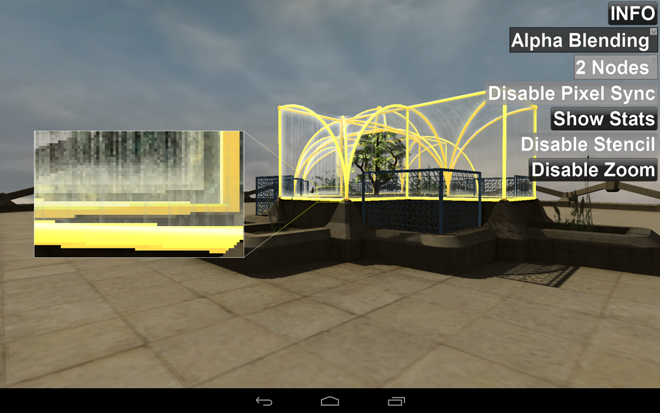
La géométrie est obtenue dans un ordre fixe : le sol suivi des objets dans le dôme, puis le dôme, et finalement les plantes extérieures. Les objets solides sont dessinés en premier et réactualisent le tampon de profondeur, les objets transparents sont ensuite dessinés dans le même ordre sans réactualisation du tampon de profondeur. La zone agrandie met en avant les effets visuels en résultant : le feuillage est à l'intérieur du dôme. Malheureusement, l'ordre de rendu signifie que tous les plans de verre, même ceux dessinés derrière le feuillage sont dessinés au-dessus. La mise à jour du tampon de profondeur de l'objet transparent crée un autre ensemble de problèmes. Habituellement, cela peut être seulement résolu en découpant les objets en de plus petits éléments et en les triant de l'avant à l'arrière-plan en fonction du point de vue de la caméra. Mais cela reste imparfait, les objets peuvent se croiser et le temps de rendu augmente au fur et à mesure que les objets sont triés et affichés.
Les figures 2 et 3 montrent l'effet visuel agrandi, avec tous les plans de verre dessinés avant le feuillage dans la figure 2 et correctement triés dans la figure 3.


IV. Transparence indépendante de l'ordre en temps réel▲
Il y a eu plusieurs tentatives pour résoudre la composition de primitives géométriques arbitrairement ordonnées sans avoir besoin de trier via le CPU ou de décomposer la géométrie des éléments croisés. Celles-ci incluent le pelage en profondeur, nécessitant pour la géométrie d'être soumise plusieurs fois et requièrent la technique du A-Buffer, là où tous les fragments contribuant à un pixel donné sont stockés dans une liste chainée, triés puis mélangés dans le bon ordre. Malgré le succès du A-Buffer dans les rendus hors ligne, il n'a pas été adopté par la communauté du rendu en temps réel en raison de son besoin illimité en mémoire et de ses faibles performances globales.
V. Une nouvelle approche▲
Plutôt que l'approche A-Buffer où toutes les données de couleur et de profondeur sont stockées dans des listes par pixel pour ensuite être triées et composées, cet exemple utilise le travail de Marko Salvi et retravaille l'équation du mélange des couleurs transparentes pour éviter la récursivité et le tri, ce qui donne une « fonction de visibilité » (Figure 4).

Le nombre d'étapes dans la fonction de visibilité correspond au nombre de nœuds utilisés pour stocker l'information de visibilité au niveau du pixel pendant l'étape de rendu. Dès leur ajout, les pixels sont stockés dans la structure de nœuds jusqu'à ce qu'elle soit pleine. Lors de la tentative d'insertion de pixels supplémentaires, l'algorithme calcule quels nœuds précédents peuvent être fusionnés pour créer la plus petite variation possible dans la fonction de visibilité tout en maintenant la taille de l'ensemble des données. L'étape finale consiste à évaluer la fonction de visibilité vis() et de composer des fragments en utilisant la formule :
kitxmlcodelatexdvp\sum a_{i} b_{i} vis(z_{i})finkitxmlcodelatexdvpL'exemple effectue le rendu de la scène via les étapes suivantes :
|
|
Figure 5 : Le chemin de rendu |
|---|
Étant donné le coût important de la lecture du Shader Storage Buffer Object dans l'étape de résolution, dû à la bande passante requise, une optimisation (dans cet exemple) consiste à utiliser le stencil buffer pour masquer les zones où les pixels transparents seraient mélangés dans la mémoire tampon principale. Cela change le rendu comme montré dans la figure 6.
|
|
Figure 6 : Chemin du Stencil Render |
|---|
L'avantage d'utiliser le stencil buffer peut être vu dans le nouveau coût de la phase de résolution, lequel est amélioré de 80 %, bien qu'il dépende fortement du pourcentage de l'écran qui est couvert par la géométrie transparente. Plus ce pourcentage est grand, plus le gain de performance est petit.
void PSOIT_InsertFragment_NoSync( float surfaceDepth, vec4 surfaceColor )
{
ATSPNode nodeArray[AOIT_NODE_COUNT];
// charge les données AOIT
PSOIT_LoadDataUAV(nodeArray);
// Mise à jour des données AOIT
PSOIT_InsertFragment(surfaceDepth,
1.0f - surfaceColor.w, // transmittance = 1 - alpha
surfaceColor.xyz,
nodeArray);
// sauve les données AOIT
PSOIT_StoreDataUAV(nodeArray);
}L'algorithme ci-dessus peut être implémenté sur n'importe quel dispositif supportant les Shader Storage Buffer Objects, mais possède un défaut important : il est possible d'avoir de multiples fragments à la volée qui mappent les mêmes coordonnées xy de la fenêtre.
Si de multiples fragments fonctionnent simultanément sur les mêmes coordonnées xy, ils liront tous les mêmes données de départ dans PSOIT_LoadDataUAV, mais finiront avec des valeurs différentes qu'ils essaieront de stocker dans PSOIT_StoreDataUAV avec le dernier écrasant les autres. Cela peut amener le programme de compression à varier entre chaque image. Vous pourrez le voir dans l'exemple en désactivant la synchronisation des pixels. L'utilisateur devrait voir un subtil miroitement sur les zones où la transparence se chevauche. La fonction de zoom a été implémentée pour que cela soit plus facile à voir. Plus le GPU peut exécuter des fragments en parallèle, plus la probabilité que le miroitement soit visible sera élevée.
Par défaut, l'exemple évite ce problème en utilisant la nouvelle fonction GLSL beginFragmentShaderOrderingINTEL(), qui peut être utilisée quand l'extension GL_INTEL_fragment_shader_ordering est présente dans le hardware. La fonction beginFragmentShaderOrderingINTEL() bloque l'exécution du fragment shader jusqu'à l'achèvement de toutes les invocations du shader des primitives précédentes aux mêmes coordonnées xy. Au renvoi de la fonction, toutes les transactions mémoire de ces invocations sont rendues visibles pour le fragment shader en cours. Cela permet de fusionner les précédents fragments pour créer la fonction de visibilité de manière déterministe. La fonction beginFragmentShaderOrderingINTEL() n'a pas d'effet sur l'exécution des fragments avec des coordonnées xy sans chevauchement.
Un exemple de la façon d'appeler beginFragmentShaderOrdering est montré à la figure 8 :
Exemple code GLSL
-----------------
layout(binding = 0, rgba8) uniform image2D image;
vec4 main()
{
... calcul la couleur de sortie
if (color.w > 0) // flux potentiel de commande non uniforme
{
beginFragmentShaderOrderingINTEL();
... lit/modifie/écrit image // accès commandé garanti
}
... aucune garantie sur l'ordre n'est faite (comme les embranchements peuvent ne pas être suivis)
beginFragmentShaderOrderingINTEL();
... mis à jour de l'image encore une fois
// pas d'ordre garanti
}Veuillez noter qu'il n'y a pas de fonction intégrée explicite pour signaler la fin de la région qui devra être ordonnée. Au lieu de cela, la région à ordonner s'étendra logiquement jusqu'à la fin de l'exécution du fragment shader.
Dans le cas de l'exemple OIT, le fragment est simplement ajouté comme montré dans la figure 9.
void PSOIT_InsertFragment( float surfaceDepth, vec4 surfaceColor )
{
// à partir de maintenant, sérialisation de tous les accès UAV (tout en respectant les autres fragments qui sont dessinés en même temps sur le même pixel)
#ifdef do_fso
beginFragmentShaderOrderingINTEL();
#endif
PSOIT_InsertFragment_NoSync( surfaceDepth, surfaceColor );
}Cela est appelé depuis tout fragment shader écrivant potentiellement des fragments transparents comme montré dans la figure 10.
out vec4 fragColor;// -------------------------------------
void main( )
{
vec4 result = vec4(0,0,0,1);
// calculs liés à l'alpha
float alpha = ALPHA().x;
result.a = alpha;
vec3 normal = normalize(outNormal);
// calculs liés à la lumière spéculaire
vec3 eyeDirection = normalize(outWorldPosition - EyePosition.xyz);
vec3 Reflection = reflect( eyeDirection, normal );
float shadowAmount = 1.0;
// calculs liés à la lumière ambiante
vec3 ambient = AmbientColor.rgb * AMBIENT().rgb;
result.xyz += ambient;
vec3 lightDirection = -LightDirection.xyz;
// calculs liés à la lumière diffuse
float nDotL = max( 0.0 ,dot( normal.xyz, lightDirection.xyz ) );
vec3 diffuse = LightColor.rgb * nDotL * shadowAmount * DIFFUSE().rgb;
result.xyz += diffuse;
float rDotL = max(0.0,dot( Reflection.xyz, lightDirection.xyz ));
vec3 specular = pow(rDotL, 8.0 ) * SPECULAR().rgb * LightColor.rgb;
result.xyz += specular;
fragColor = result;
#ifdef dopoit
if(fragColor.a > 0.01)
{
PSOIT_InsertFragment( outPositionView.z, fragColor );
fragColor = vec4(1.0,1.0,0.0,0.0);
}
#endif
}Seuls les fragments ayant une valeur alpha au-dessus d'un seuil sont ajoutés au Shader Storage Buffer Object, sélectionnant efficacement tout fragment qui ne fournirait pas de données significatives à la scène.
VI. Compiler l'exemple▲
Installation des dernières versions du SDK et du NDK Android.
Ajout du SDK et du NDK au chemin d'accès :
export PATH=$ANDROID_NDK/:$ANDROID_SDK/tools/:$PATHPour préparer l'environnement, il faut :
- Se placer dans le dossier OIT_2014\OIT_Android ;
-
À faire une fois : initialiser le projet
Sélectionnezandroid update project -path . --target android-19 -
Compiler le composant du NDK
SélectionnezNDK-BUILD -
Compiler l'APK
Sélectionnezant debug -
Installer l'APK
Sélectionnezadb install -r bin\NativeActivity-debug.apk ou ant installd - Exécuter l'APK
VII. Conclusion▲
L'exemple explique comment la recherche de transparence adaptative et indépendante de l'ordre de rendu présenté par Marko Salvi, Jefferson Montgomery, Karthik Vaidyanathan, et Aaron Lefohn originalement effectuée sur des cartes graphiques haut de gamme avec DirectX 11* peut être implémentée en temps réel sur une tablette Android utilisant OpenGL ES 3.1 et l'ordonnancement du fragment. L'algorithme fonctionne dans une empreinte mémoire fixe qui peut varier selon la fidélité de rendu souhaitée. Les optimisations telles que l'utilisation du stencil buffer permettent à cette technique d'être implémentée sur une large étendue de matériels avec des performances acceptables, fournissant ainsi une solution pratique pour un des plus difficiles problèmes de rendu en temps réel. Les principes montrés dans l'exemple peuvent être appliqués à une variété d'autres algorithmes qui créeraient normalement des listes chaînées par pixel incluant les techniques d'ombrage volumétrique et l'anti-aliasing post traitement.
Retrouvez toutes les ressources et outils Intel pour les développeurs Android sur la Zone des Développeurs Intel Android.